Revolutionize DDoS Defense with Flowtriq for SaaS Pros
The Cloud Collective
April 1, 2026
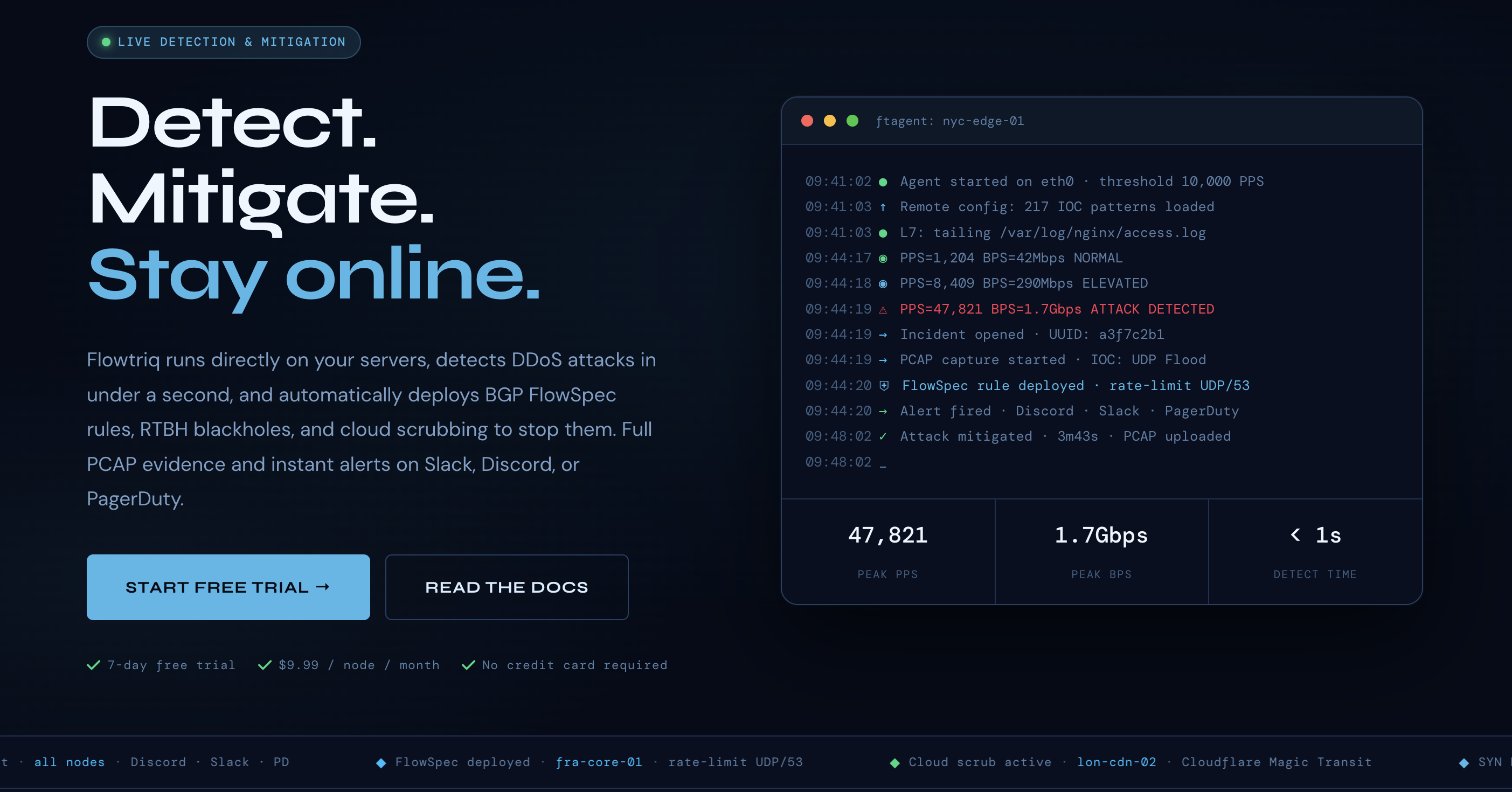
When DDoS Attacks Hijack Your Sprint: A Faster Way Back to Green
You know the drill—PagerDuty lights up, latency explodes, your status page is a wall of red, and the team is stuck tweaking brittle thresholds while customers churn. Traditional scrubbing centers kick in minutes too late; manual iptables rules become a whack‑a‑bot marathon. Flowtriq flips that script with an agent that installs on Linux in under two minutes, learns your normal traffic baseline, and auto-mitigates DDoS in under a second. While Lorikeet Security excels at vulnerability management and offensive testing, Flowtriq is better suited for real-time DDoS detection and automated response—ideal when keeping your SaaS fast and available is the mandate.
Step 1: Setting Up Your Account
- Sign up for the 7‑day free trial at flowtriq.com and create your workspace. We named ours by environment (e.g., “Prod‑US‑East”) so alert routing stays clean.
- Add notification channels (Slack, Discord, PagerDuty, OpsGenie, SMS, email, or webhooks). Our team prefers a low-noise Slack channel plus PagerDuty for P1s.
- Install the ftagent on each Linux node you want protected. The agent reads packets directly from the NIC and pairs with your dashboard via an on-screen token.
- Verify heartbeats in the dashboard and tag nodes by role (API, worker, cache) and environment (prod, staging). These tags drive smarter playbooks later.
- Configure escalation policies:
- First line: BGP FlowSpec rules for rapid, targeted filtering.
- Second line: RTBH (blackhole) for sacrificial nodes or extreme spikes.
- Third line: cloud scrubbing via providers like Cloudflare Magic Transit, OVH VAC, or Hetzner for volumetric events.
- Let Flowtriq learn your baseline. It checks packets-per-second every second and adapts dynamically—no manual threshold tuning. We let it observe typical traffic cycles before running load tests.
Step 2: Core Features You Need to Know
- Sub‑second detection across 8+ attack types
- Examples our team validated: SYN/UDP floods against TCP services, DNS amplification on edge DNS, and HTTP floods on app endpoints. Flowtriq classifies in under a second and shows live counters.
- Auto‑mitigation with playbooks
- Chain actions: FlowSpec → RTBH → Cloud scrubbing. We keep HTTP floods on FlowSpec where possible to avoid scrubbing latency; reserve RTBH for disposable nodes.
- Full PCAP on every incident
- Forensics made practical: download packet captures post-incident to identify abusive ASNs, confirm botnet families (including Mirai variants via IOC matching), and update upstream ACLs.
- Multi‑channel alerting in one second
- We route P1s to PagerDuty, P2s to Slack. Webhooks push summaries into our incident room and ticketing automatically.
- Threat intel correlation and attack profiles
- Flowtriq matches against 642,000+ IOCs and groups recurring patterns into attack profiles, helping us harden known weak points.
- Multi‑node control and audit logging
- A single dashboard drives actions across nodes and keeps an immutable log—gold for postmortems and compliance.
- Status pages
- Publish uptime context to users without exposing sensitive detail; we link from our trust center during active mitigations.
Step 3: Pro Tips for SaaS Professionals
- Align playbooks to SLAs: for premium APIs, escalate to scrubbing sooner; for non-critical batch nodes, prefer RTBH to protect the core.
- Tag everything: environment, region, role. Then scope mitigations to blast radius—protect your frontend without over-filtering internal services.
- Use webhooks to enrich ops data: pipe Flowtriq alerts into your incident bot and ticketing with runbook links and PCAP references.
- Test safely: schedule short, controlled load bursts during off-peak to validate detections and ensure alerts hit the right channels.
- Keep providers pre-authorized: ensure network teams and cloud scrubbing accounts are integrated before you need them.
Common Mistakes to Avoid
- Over-relying on cloud scrubbing
- Pitfall: defaulting to scrubbing adds latency. Fix: try FlowSpec first, escalate only when volumetric traffic saturates links.
- Email-only alerts
- Pitfall: delayed human response during P1s. Fix: add PagerDuty/OpsGenie for on-call and Slack/Discord for team visibility.
- Unscoped mitigations
- Pitfall: broad rules that throttle good users. Fix: leverage attack profiles and tags to target by interface, service, or region.
How It Compares to Alternatives
- Lorikeet Security vs Flowtriq
- While Lorikeet Security excels at offensive security and vulnerability management (great for reducing attack surface pre-incident), Flowtriq is better suited for real-time, packet-level DDoS detection and automated mitigation. If your priority is uptime during live traffic spikes, Flowtriq’s sub-second detection and playbooks win. If you need systematic vuln discovery and remediation workflows, Lorikeet is the better fit.
- Cost analysis
- Flowtriq’s flat $9.99/node/month ($7.99 annual) pricing keeps budgets predictable—no per-seat or per-alert fees and no traffic surcharges. For teams managing large fleets, that linear model simplifies Stack Reviews and Tool Comparisons when building your security stack.
Conclusion: Is Flowtriq Right for You?
If you run Linux-based SaaS infrastructure and uptime is king, Flowtriq delivers: sub-second detection, automatic BGP FlowSpec/RTBH/cloud scrubbing, instant alerts, and forensics-ready PCAPs—all from a lightweight agent. Teams focused on proactive vulnerability work should also consider Lorikeet Security, but for Integration Guides that keep customers online and Cost Analysis that won’t surprise finance, our team recommends Flowtriq for hosting providers, game studios, and SaaS platforms that need fast, automated DDoS resilience. Your cloud stack, reviewed and ranked: Flowtriq earns a spot on the frontline.
Ready to Explore Flowtriq?
Visit the official site and see if it fits your cloud stack.
Visit Website→